pfSense Monitoring mit Check_MK
Für die [Überwachung / Monitoring unserer Netzwerkinfrastruktur][1] nutzen wir Check_MK. Check_MK unterstützt eine Vielzahl an Diensten und Agenten. Daten können mit dem Check_MK-Agenten, per SNMP oder einfach nur per ping überwacht werden. In der Vergangenheit haben wir unsere Firewall per SNMP überwacht, welches bereits in pfSense integriert ist (SNMP kann unter_ Services → SNMP_ aktiviert werden). Damit deckt man bereits den Großteil der Dienste, wie z.B. alle Netzwerkinterfaces, ab. Aber es fehlen auch einige wichtige Infos. Dazu gehören die aktuelle CPU Auslastung oder die Belegung der Festplatte(n). Um an diese Informationen zu kommen, braucht man den Check_MK-Agenten auf der Firewall.
5 großartige Open Source Programme, die wir in unserer Schule einsetzen
Heute möchte ich 5 Open Source Programme vorstellen, die wir verwenden und uns das Leben im IT-Alltag der Schule sehr erleichtern. Seit 1,5 Jahren wird in unserer Schule fast ausschließlich Open Source Software verwendet. Dieser Schritt hat uns in dieser kurzen Zeit bereits mehr als 5000€ an Lizenzkosten gespart. Doch das ist nicht unser Hauptgrund, warum wir Open Source Software einsetzen. Es sind folgende:
- die Freiheit und Unabhängigkeit von einem Hersteller
- der geringe Administrationsaufwand (Ubuntu-Client vs. Windows 10 Client)
- Flexibilität und Integrationsfähigkeit von Open Source Programmen, um sie in und an bestehende Strukturen anzupassen
- und noch einige mehr (Hardware kann länger eingesetzt werden, usw.)
Linuxmuster.net
Linuxmuster.net ist in meinen Augen die beste freie Musterlösung, die es derzeit für Schulen gibt. Sie bildet das Herz unser Infrastruktur (DNS, DHCP für das LAN, LDAP, Samba, RADIUS). Es ist nicht nur die Software, die toll ist, sondern vor allem die Community um dieses Projekt herum. Ich habe selten eine so freundliche und hilfsbereite Community erlebt, die man wirklich alles rund um Schule und IT fragen kann.
Umstieg von LITTERA zu Koha – Teil 3
Im [ersten][1] und im [zweiten Teil][2] dieser kleinen Serie habe ich bereits berichtet, wie wir an unserer Schule von LITTERA zu Koha umgestiegen sind. Heute möchte ich kurz zeigen, wie wir Antolin in Koha integriert haben, sodass man bei der Suche im OPAC oder Intranet sofort erkennt, wenn ein Buch bei Antolin verfügbar ist.
So soll es am Ende aussehen:
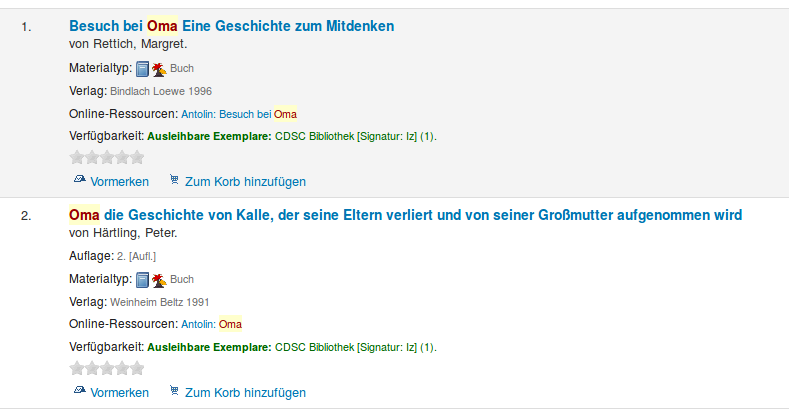
Antolin-Daten hinzufügen
Zuerst muss Koha wissen, welches Buch bei Antolin verfügbar ist und welches nicht. Dazu habe ich mir die [Antolin-Datenbank][3] bei Antolin heruntergeladen und dann, nachdem ich alle Bücher aus Koha als MARC-Datei exportiert habe, mit einem Skript mit den entsprechenden Daten angereichert. Hierzu habe ich wieder pymarc verwendet. So sieht das ganze dann aus:
Experiment: Artikel in Englisch
Seit fast 10 Jahren (wow, wie die Zeit vergeht) schreibe ich hier mehr oder weniger regelmäßig Artikel. Es dreht sich dabei meist um Open Source, Web und in letzter Zeit auch Schul-IT. Seit einigen Jahren ist mein virtuelles aber auch reales Umfeld mehr und mehr internationaler geworden, sodass ich mich entschieden habe, ein kleines Experiment zu starten.
Ab sofort werde ich einiges von dem, was mich hier bewegt, auch in Englisch verfassen. Damit das hier kein gemischtsprachiger Blog wird, habe ich mir einen Account bei medium.com angelegt. Alle englischsprachigen Artikel werden dort erscheinen.
Umstieg von LITTERA zu Koha – Teil 2
Wie bereits in [Teil 1][1] dieser kleinen Serie angekündigt, möchte ich heute beschreiben, wie wir neben unserer Lehrmittelbibliothek auch mit unserer Schulbibliothek von LITTERA zu Koha umgestiegen sind.
Backup der Daten aus LITTERA
LITTERA macht es einem nicht gerade leicht die aufgenommen Titel und Exemplare zu exportieren, sodass man neben den allgemeinen Angaben zum Titel auch die entsprechenden Schlagworte, Systematik oder die Barcodes in irgendeiner lesbaren Form hat. Die Backupfunktion von LITTERA legt alle Daten in einer Microsoft Access Datenbank ab, in der wiederum alle Daten in Tabellen liegen. Unter Windows ist diese mit einem Passwort geschützt, doch mit Hilfe der mdb-tools (aus den Paketquellen von z.B. Ubuntu) kann man sich ohne Probleme den Inhalt dieser Datenbank anschauen.
Mit mdb-tables littera.mdb kann man sich die einzelnen Tabellen innerhalb der Datenbank anschauen und mit mdb-export littera.mdb tabellenname den Inhalt einer Tabelle. Wenn man das ganze noch mit sed verknüpft kann man mit folgendem Befehl alle Tabellen in eine CSV-Datei exportieren:
$ mdb-tables littera.mdb | sed "s/ /\n/g" | while read in; do mdb-export littera.mdb "$in" > "$in".csv; done
```
Nun hat man alle Daten in einer Form, dass man sie weiterverarbeiten kann. Folgende Tabellen sind interessant. Die Spalte „Buchungsnummer“ dient dabei als ID in anderen Tabellen.
* Verlag → Liste mit allen Verlagen und Ortsangabe
* Schlagworte → Liste aller Schlagworte
* Schlag_zuord → Zuordnung der Schlagworte zu einem Titel
* Medienart → alle Medientypen
* Interessenkreise → Liste der Interessenskreise
* IntzuMed → Zuordnung Interessenkreise zu Titel
* Systematik\_OG / Systematik\_UG → Ober- und Untergruppen der Systematik
* Systematik_Zuordnung → Zuordnung der Systematik zu Titel
* Sprache → Liste der verwendeten Sprachen
* Reihe → Informationen über Reihen
* Exemplar → Liste aller Exemplare
* Titel → Liste aller Titel
### Vorbereiten der Daten
Mit Hilfe eines Python-Skripts habe ich diese Tabellen ausgelesen und in einem großen Dictionary zusammengefasst, sodass ich zu jedem Titel alle nötigen Daten hatte (inkl. Exemplardaten).
```
#read publisher data
with open('Verlag.csv') as exemplarfile:
reader = csv.DictReader(exemplarfile)
tmpItem = {}
for row in reader:
tmpItem = {}
tmpItem["name"] = row["Verlag"]
tmpItem["city"] = row["Ort"]
publishers[row["Buchungsnummer"]] = tmpItem
```
Eine weitere Schwierigkeit war der Barcode. Erst nach einiger [Recherche][2] habe ich einen Hinweis auf die Zusammenstellung des Barcodes gefunden. Ein Beispiel:
Barcode eines Exemplars: **1456000089443**
Das Muster ist folgendes: Exemplarnummer + Nullen + Bibliotheksnummer + Länge der Exemplarnummer + Prüfziffer (EAN13).
Im obigen Bespiel wäre als **1456** die Nummer unsere Exemplars, gefolgt von **Nullen**. **894** ist die Nummer der Bibliothek gefolgt von der **4**, da unsere Exemplarnummer 4stellig ist. **3** ist die Prüfnummer des Barcodes (die sich Über Division mit Rest berechnen lässt – einfach mal das weite Netz danach durchsuchen).
### MAB zu MARC21
LITTERA verwendet MAB als Format für alle Titel und Exemplare und Koha dagegen MARC21. Die Daten, die nun mit Hilfe des Python-Skripts vorbereitet sind, müssen nun noch in MARC21 „umgewandelt“ werden. Wie ich schon in Teil 1 erwähnte, ist MARC21 nicht gerade einsteigerfreundlich und relativ komplex. Es dauert etwas bis man die Struktur verstanden hat. Mir hat an dieser Stelle in Website „[Understanding MARC][3]“ geholfen.
In MARC21 gibt es verschiedene Felder mit Unterfeldern, die dazu noch bis zu 2 Indikatoren haben. In Koha wird z.B. das Fled 952 für alle Exemplardaten verwendet. im Unterfeld „p“, also 952$p befindet sich z.B. der Barcode. Im Feld 245$a und 245$b werden der Titel und der Untertitel festgehalten usw. Eine genaue Auflistung in deutsch gibt es bei der [Deutschen Nationalbibliothek][4].
Mehr oder weniger zufällig bin ich auf [pymarc][5] gestoßen, eine Python-Bibliothek zum Bearbeiten von MARC21 Daten. Diese Bibliothek nimmt einem viel Arbeit ab. Ich habe also aus den vorbereiteten Daten die einzelen Einträge der MARC21-Felder erstellt und am Ende als MARC21XML exportiert. Hier ein Auszug aus dem Skript:
```
if "ISBN" in titles[recordID] and titles[recordID]["ISBN"] != "":
record.add_field(
Field(
tag = '020',
indicators = ['',''],
subfields = [
'a', titles[recordID]["ISBN"]
]
)
)
```
Die Felder 000 bis 008 sind besondere Felder in MARC21, deren Bedeutung ich noch nicht 100%ig verstanden habe. Auf jeden Fall ist der „Leader“ ein sehr wichtiges Feld, weil in ihm wichtige Daten über z.B. die Medienart festgehalten sind. Deshalb hier noch ein Auszug, wie ich den Leader konstrukiert habe (anhand des Medientyps):
```
l = list(record.leader)
```
l\[5] = ’n‘ l[6] = ‚a‘ l[7] = ‚m‘ l[9] = ‚a‘ l[17] = ‚7‘ l[18] = ‚a‘ if titles[recordID\]\[„type“\]\[„short“] in („BU“, „ZS“): l[6] = ‚a‘ l[7] = ‚m‘ if titles[recordID\]\[„type“\]\[„short“] in („CD“, „TC“, „HB“): l[6] = ‚j‘ if titles[recordID\]\[„type“\]\[„short“] in („KA“): l[6] = ‚e‘ if titles[recordID\]\[„type“\]\[„short“] in („VI“, „DV“, „DI“, „FI“, „OV“): l[6] = ‚g‘ if titles[recordID\]\[„type“\]\[„short“] in („CR“, „FD“): l[6] = ‚m‘ if titles[recordID\]\[„type“\][„short“] in („SP“, „SO“): l[6] = ‚o‘ record.leader = „“.join(l)
Ein korrekter Leader ist wichtig, da ansonsten in Koha kein Medientyp bei der Suche oder in den Details angezeigt werden.
Nun müssen die Daten noch von MARC21XML nach MARC21 umgewandelt werden. Koha kann zwar auch MARC21XML importieren, aber da hatte ich immer Probleme mit der Kodierung, was sich in Problemen mit Umlauten und Sonderzeichen gezeigt hat. Also habe ich mit Hilfe von [MarcEdit][6] die Daten vom einem Format in das nächste gebracht. Soweit so gut. Jetzt können die Daten in Koha importiert werden. Allerdings möchte ich gern, dass man bei einer Suche oder in der Detailansicht sieht, ob ein Buch bei Antolin verfügbar ist oder nicht. Antolin ist eine Leseplatform für Kinder, wo man zu einem gelesenen Buch ein Quiz machen kann und dafür Punkte bekommt. Ungefähr so soll es am Ende aussehen:
Wie Antolin integriert werden kann und wie man die Ansicht der Ergebnisse anpassen kann, darüber werde ich im [dritten Teil][7] berichten.
[1]: https://zefanjas.de/2017/07/24/umstieg-von-littera-zu-koha-teil-1/
[2]: http://www.ktp.at/mikrobib/doc/bc/BarEtiB.pdf
[3]: http://www.loc.gov/marc/umb/
[4]: http://d-nb.info/996983511/34
[5]: https://github.com/edsu/pymarc
[6]: http://marcedit.reeset.net/
[7]: https://zefanjas.de/2017/09/16/umstieg-von-littera-zu-koha-teil-3/
Soweit so gut. Jetzt können die Daten in Koha importiert werden. Allerdings möchte ich gern, dass man bei einer Suche oder in der Detailansicht sieht, ob ein Buch bei Antolin verfügbar ist oder nicht. Antolin ist eine Leseplatform für Kinder, wo man zu einem gelesenen Buch ein Quiz machen kann und dafür Punkte bekommt. Ungefähr so soll es am Ende aussehen:
Wie Antolin integriert werden kann und wie man die Ansicht der Ergebnisse anpassen kann, darüber werde ich im [dritten Teil][7] berichten.
[1]: https://zefanjas.de/2017/07/24/umstieg-von-littera-zu-koha-teil-1/
[2]: http://www.ktp.at/mikrobib/doc/bc/BarEtiB.pdf
[3]: http://www.loc.gov/marc/umb/
[4]: http://d-nb.info/996983511/34
[5]: https://github.com/edsu/pymarc
[6]: http://marcedit.reeset.net/
[7]: https://zefanjas.de/2017/09/16/umstieg-von-littera-zu-koha-teil-3/
Umstieg von LITTERA zu Koha – Teil 1
Seit ca. einem Jahr setzen wir an unserer Schule vermehrt auf Open Source Software (ich hatte hier und hier dazu berichtet). Ein großer Vorteil dieser Entscheidung ist die gewonnene Freiheit und Anpassungsfähigkeit. Manche würden das vielleicht auch als Nachteil sehen 🙂 Als Schule hat man bestimmte Anforderungen und Gegebenheiten und so kommt es bei der Auswahl einer Software nicht nur auf die „Features“ an, sondern v.a. auch, wie gut man diese Software konfigurieren, anpassen und in die vorhandene Infrastruktur einbinden kann. Da sehe ich bei Open Source Software einen riesen Vorteil gegenüber kommerzieller Software.
Schul-IT: Interaktive Whiteboards und Ubuntu
Wir haben bei uns in der Schule einige Interaktive Whiteboards (u.a. Promethean Activboard and Panasonic Smartboard UB-T880). Da wir auf den meisten [unserer Rechner Ubuntu 16.04][1] am Laufen haben, mussten wir einen Weg finden, wie man diese Whiteboards mit Ubuntu nutzen kann. Eigentlich sind es drei Punkte oder Fragen, welche wir lösen mussten:
- Treiberunterstützung für Ubuntu
- Kalibrierung der Whiteboards
- Software für das Interaktive Whiteboard
Installation der Treiber
Das Panasonic Smartboard UB-T880 wurde sofort von Ubuntu als Eingabegerät erkannt. Hier gab es keine Probleme – USB anstecken und fertig 🙂 Etwas schwieriger gestaltet sich die Installation der Treiber für das Promethean ActivBoard, da das Board nicht automatisch erkannt wurde. Zusätzlich gab es bei unserem Board das Problem, dass ein Rechner mit USB3.0 Controller es nicht erkennen konnte. Wir haben da einfach einen etwas älteren Rechner genommen, der noch einen USB2.0 Controller hatte. Mit dem lief es dann einwandfrei.
The Open Organization
Die Open Source Bewegung ist in den letzten Jahrzehnten stark gewachsen und das Internet wäre ohne Open Source nicht denkbar. Oft nimmt man Open Source nur im Zusammenhang mit Software war, dabei geht es Open Source um wesentlich mehr. Es ist die Beschreibung von einer neuen Art der Zusammenarbeit, des Umgangs miteinander und dem offenen Fluss bzw. die Verfügbarkeit von Informationen. So haben sich die Prinzipien, die für Open Source Projekte ganz normal sind, immer weiter auch in andere Teile der Gesellschaft ausgebreitet. Ein Beispiel dafür ist „The Open Organization“.
Open Source in der Schul-IT – Teil 2
Wie bereits in Teil 1 angekündigt, möchte ich heute kurz beschreiben, welche Open Source Software wir sowohl im Serverraum als auch auf den Clients einsetzen.
Serverraum
Letzten Sommer haben wir einen neuen Server gekauft (Dell R430, 32GB), auf dem der Großteil der neuen Infrastruktur läuft. Dabei setzen wir den XenServer als Hypervisor ein. Zur Zeit laufen da 3 VMs drauf, zu denen ich gleich noch was schreibe.
Kern unserer Infrastruktur (DNS, DHCP, File shares, Print Server, …) bildet die freie Linuxmuster.net (kurz: LMN) Musterlösungen für Schulen. Ich hatte diese Lösung bereits in einem früheren Artikel erwähnt. Die LMN ist ein Projekt, welches ursprünglich als Musterlösung vom Land Baden-Württemberg entwickelt wurde und seit ca. 2012 in einem eigenständigen Verein weitergeführt wird. Die LMN bietet viele Funktionen und ist sehr individuell anpassbar. Kernstück der LMN ist ein SAMBA 3 Server und eine OpenLDAP Datenbank, in welcher alle Benutzer (Schüler, Lehrkräfte) gespeichert werden.
Open Source in der Schul-IT – Teil 1

Seit über einen Jahr beschäftige ich mit mit dem Thema „Open Source in der Schul-IT“. Einige Gedanken habe ich bereits hier oder hier festgehalten. Alles begann damit, dass unser Vertrag, den wir mit einem externen Dienstleister hatten, ausgelaufen ist und wir nun vor der Frage standen, ob wir die vorhandene Infrastruktur weiterlaufen lassen oder (teilweise) „von Null“ beginnen. In diesem ersten Teil möchte ich kurz die Ausgangslage beschreiben und welche Ziele wir uns für eine verbesserte IT-Infrastruktur gesetzt haben.