Below you will find pages that utilize the taxonomy term “Bibliothek”
23. July 2020
Koha LDAP / AD Verbindung einrichten
Koha ist eine freie Bibliothekssoftware, die wir an unserer Schule verwenden. Wir verwalten damit unsere Lehrmittel- als auch unsere Schulbibliothek. Vorher haben wir LITTERA dafür verwendet, doch seit letztem Sommer sind wir komplett auf Koha umgestiegen. Der Kern unserer Schulinfrastruktur ist ein linuxmuster.net Schulserver. Jeder Schüler und Kollege hat einen schulinternen Benutzernamen, den man für die Anmeldung an unseren Schulcomputern braucht. linuxmuster.net bringt dafür einen LDAP Server mit. In diesem Artikel möchte ich zeigen, wie man in Koha die LDAP Verbindung einrichtet, sodass sich alle Benutzer in der Bibliothek mit ihrem schulinternen Login anmelden können.
6. October 2018
Teil 6: Ausleihkonditionen – Wie man Koha installiert und für Schulen einrichtet
Bisher haben wir Koha installiert, konfiguriert und erste Medien katalogisiert. Die Barcodes sind gedruckt und kleben in den Büchern. Eigentlich wartet alles darauf, dass wir endlich die Bücher an unsere Leser ausleihen können. Ein letzter Schritt fehlt noch und um den soll es heute gehen: die Ausleihkonditionen. Damit können wir festlegen, wer welche Medien, wie lange ausleihen darf. Aber auch Gebühren, Verlängerungen und noch vieles mehr können wir in Koha festlegen, bevor die ersten Bücher die Bibliothek verlassen.
22. September 2018
Teil 5: Etikettendruck – Wie man Koha installiert und für Schulen einrichtet
Koha ist eines der besten Open Source Projekte, die ich kenne. Es ist eine sehr flexible Lösung, die etwas Zeit braucht, bis man sich darin zurechtfindet. Einen Großteil der Punkte haben wir aber bereits abgearbeitet, v.a. die Installation (Teil 1) und das bibliografische Framework (Teil 2). Im letzten Teil haben wir einige Bücher aufgenommen. Bevor wir jedoch anfangen können, Bücher oder andere Medien auszuleihen, braucht jedes Buch einen Barcode. Weiterhin müssen wir Regeln für die Ausleihe festlegen. Heute geht es um den Etikettendruck. Dieser Artikel ist ein Teil einer Serie:
5. September 2018
Teil 4: Katalogisierung – Wie man Koha installiert und für Schulen einrichtet
Nach einer etwas zu lang geratenen Pause geht es heute weiter in der Serie „Wie man Koha installiert und für Schulen einrichtet“. Nachdem das System installiert, das bibliographische Framework eingerichtet und grundlegende Einstellungen vorgenommen sind, werden wir uns in diesem Artikel mit der Aufnahme von Büchern in Koha bzw. der Katalogisierung beschäftigen. Dieser Artikel ist ein Teil einer Serie:
- Installation und Einrichtung einer ersten Bibliothek
- Das bibliografische Framework
- Grundeinstellungen
- Buchaufnahme
- Drucken von Etiketten
- Ausleihkonditionen
- Verbinden mit einem Z.39.50 / SRU Server
- Benachrichtigungen und Erinnerungen
- Mahnungen und Gebühren
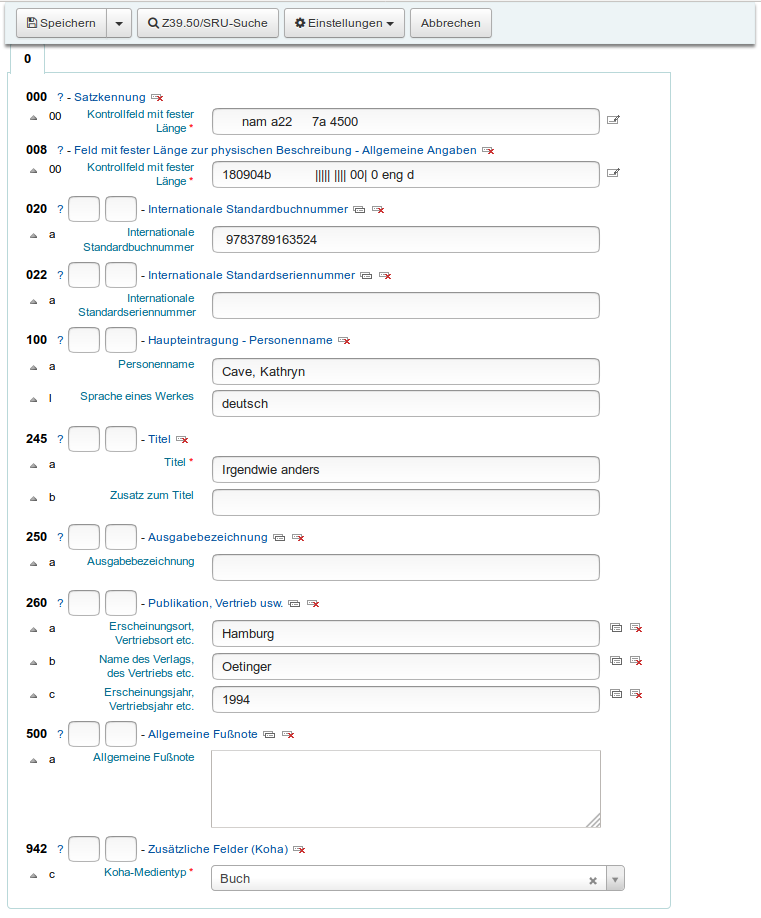
Buchaufnahme {.wp-block-heading} Ein Buch können wir über den Punkt
Katalogisierung → Neuer Titel → Schnellaufnahme aufnehmen.
11. April 2018
Teil 3: Grundeinstellungen – Wie man Koha installiert und für Schulen einrichtet
Nachdem wir Koha im ersten Teil installiert und im zweiten Teil das Bibliografische Framework eingerichtet haben, geht es heute darum einige Grundeinstellungen in Koha vorzunehmen. Wir wollen neue Kategorien für unsere Benutzer und Medien einrichten, sowie einige Systemparameter ändern.
Dieser Artikel ist ein Teil einer Serie:
- Installation und Einrichtung einer ersten Bibliothek
- Das bibliografische Framework
- Grundeinstellungen
- Buchaufnahme
- Drucken von Etiketten
- Ausleihkonditionen
- Verbinden mit einem Z.39.50 / SRU Server
- Benachrichtigungen und Erinnerungen
- Mahnungen und Gebühren
Grundeinstellungen
Bibliothek
Wir loggen uns wieder mit unseren Administrator-Account aus Teil 1 ein und wählen Administration → Basisparameter → Bibliotheken und Gruppen. In der Tabelle klicken wir auf Bearbeiten und können nun weitere Angaben zu unserer Bibliothek machen.
30. March 2018
Teil 2: Das bibliografische Framework – Wie man Koha installiert und für Schulen einrichtet
Im [ersten Teil dieser Serie][1] haben wir bereits Koha installiert. Bevor wir ein Buch aufnehmen oder verleihen können, müssen noch einige Einstellungen vorgenommen werden. Ein großes Thema ist das bibliografische Framework. Bei der Installation haben wir bereits MARC21 gewählt. Was das ist, warum es wichtig ist und wie wir das Framework für eine Schule anpassen können, darum geht es in diesem 2. Teil.
Dieser Artikel ist ein Teil einer Serie:
9. March 2018
Teil 1: Installation – Wie man Koha installiert und für Schulen einrichtet
Koha, ein [integriertes Bibliothekssystem][1], ist eines der [besten Open Source Projekte][2], das ich kenne. Wir verwenden es in unserer [Schul- und Lehrmittelbibliothek][3]. Weltweit wird es von vielen Schulen, Universitäten und natürlich Bibliotheken verwendet. Es bringt sehr viele Features mit und man kann es sehr flexibel konfigurieren und anpassen. Jedoch hat es einen Nachteil: Wenn man bisher wenig mit dem Bibliothekswesen zu tun hatte, ist der Einstieg recht steil, weniger in Koha, sondern in das [bibliografische Datenformat MARC 21][4]. Deshalb möchte ich in dieser Artikelreihe zeigen, wie man Koha installiert und für Schulen einrichtet.
24. January 2018
Wie man das Koha „auto increment“ Problem lösen kann
Wir verwenden [Koha für unsere Bibliothek][1], eine sehr mächtige und [tolle Open Source Software][2]. Auf Mailingliste des Projekts hatte ich bereits vom „Koha auto increment“ – Problem gelesen und hoffte, dass es uns nicht betraf. Doch vor einigen Wochen kam einer unserer Mitarbeiter der Schulbibliothek zu mir und gab mir ein Buch, dass sich nicht zurückgeben ließ. Jedes mal, wenn man versuchte, das besagte Buch zurückzugeben, bekam man folgende Fehlermeldung:
16. September 2017
Umstieg von LITTERA zu Koha – Teil 3
Im [ersten][1] und im [zweiten Teil][2] dieser kleinen Serie habe ich bereits berichtet, wie wir an unserer Schule von LITTERA zu Koha umgestiegen sind. Heute möchte ich kurz zeigen, wie wir Antolin in Koha integriert haben, sodass man bei der Suche im OPAC oder Intranet sofort erkennt, wenn ein Buch bei Antolin verfügbar ist.
So soll es am Ende aussehen:
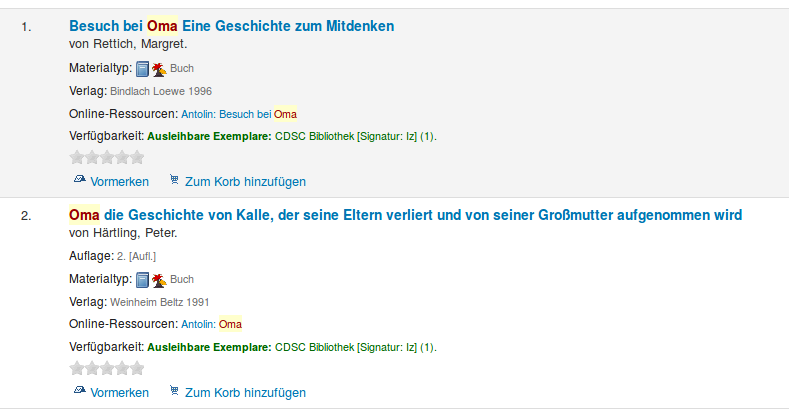
Antolin-Daten hinzufügen
Zuerst muss Koha wissen, welches Buch bei Antolin verfügbar ist und welches nicht. Dazu habe ich mir die [Antolin-Datenbank][3] bei Antolin heruntergeladen und dann, nachdem ich alle Bücher aus Koha als MARC-Datei exportiert habe, mit einem Skript mit den entsprechenden Daten angereichert. Hierzu habe ich wieder pymarc verwendet. So sieht das ganze dann aus:
26. July 2017
Umstieg von LITTERA zu Koha – Teil 2
Wie bereits in [Teil 1][1] dieser kleinen Serie angekündigt, möchte ich heute beschreiben, wie wir neben unserer Lehrmittelbibliothek auch mit unserer Schulbibliothek von LITTERA zu Koha umgestiegen sind.
Backup der Daten aus LITTERA
LITTERA macht es einem nicht gerade leicht die aufgenommen Titel und Exemplare zu exportieren, sodass man neben den allgemeinen Angaben zum Titel auch die entsprechenden Schlagworte, Systematik oder die Barcodes in irgendeiner lesbaren Form hat. Die Backupfunktion von LITTERA legt alle Daten in einer Microsoft Access Datenbank ab, in der wiederum alle Daten in Tabellen liegen. Unter Windows ist diese mit einem Passwort geschützt, doch mit Hilfe der mdb-tools (aus den Paketquellen von z.B. Ubuntu) kann man sich ohne Probleme den Inhalt dieser Datenbank anschauen.
Mit mdb-tables littera.mdb kann man sich die einzelnen Tabellen innerhalb der Datenbank anschauen und mit mdb-export littera.mdb tabellenname den Inhalt einer Tabelle. Wenn man das ganze noch mit sed verknüpft kann man mit folgendem Befehl alle Tabellen in eine CSV-Datei exportieren:
$ mdb-tables littera.mdb | sed "s/ /\n/g" | while read in; do mdb-export littera.mdb "$in" > "$in".csv; done
```
Nun hat man alle Daten in einer Form, dass man sie weiterverarbeiten kann. Folgende Tabellen sind interessant. Die Spalte „Buchungsnummer“ dient dabei als ID in anderen Tabellen.
* Verlag → Liste mit allen Verlagen und Ortsangabe
* Schlagworte → Liste aller Schlagworte
* Schlag_zuord → Zuordnung der Schlagworte zu einem Titel
* Medienart → alle Medientypen
* Interessenkreise → Liste der Interessenskreise
* IntzuMed → Zuordnung Interessenkreise zu Titel
* Systematik\_OG / Systematik\_UG → Ober- und Untergruppen der Systematik
* Systematik_Zuordnung → Zuordnung der Systematik zu Titel
* Sprache → Liste der verwendeten Sprachen
* Reihe → Informationen über Reihen
* Exemplar → Liste aller Exemplare
* Titel → Liste aller Titel
### Vorbereiten der Daten
Mit Hilfe eines Python-Skripts habe ich diese Tabellen ausgelesen und in einem großen Dictionary zusammengefasst, sodass ich zu jedem Titel alle nötigen Daten hatte (inkl. Exemplardaten).
```
#read publisher data
with open('Verlag.csv') as exemplarfile:
reader = csv.DictReader(exemplarfile)
tmpItem = {}
for row in reader:
tmpItem = {}
tmpItem["name"] = row["Verlag"]
tmpItem["city"] = row["Ort"]
publishers[row["Buchungsnummer"]] = tmpItem
```
Eine weitere Schwierigkeit war der Barcode. Erst nach einiger [Recherche][2] habe ich einen Hinweis auf die Zusammenstellung des Barcodes gefunden. Ein Beispiel:
Barcode eines Exemplars: **1456000089443**
Das Muster ist folgendes: Exemplarnummer + Nullen + Bibliotheksnummer + Länge der Exemplarnummer + Prüfziffer (EAN13).
Im obigen Bespiel wäre als **1456** die Nummer unsere Exemplars, gefolgt von **Nullen**. **894** ist die Nummer der Bibliothek gefolgt von der **4**, da unsere Exemplarnummer 4stellig ist. **3** ist die Prüfnummer des Barcodes (die sich Über Division mit Rest berechnen lässt – einfach mal das weite Netz danach durchsuchen).
### MAB zu MARC21
LITTERA verwendet MAB als Format für alle Titel und Exemplare und Koha dagegen MARC21. Die Daten, die nun mit Hilfe des Python-Skripts vorbereitet sind, müssen nun noch in MARC21 „umgewandelt“ werden. Wie ich schon in Teil 1 erwähnte, ist MARC21 nicht gerade einsteigerfreundlich und relativ komplex. Es dauert etwas bis man die Struktur verstanden hat. Mir hat an dieser Stelle in Website „[Understanding MARC][3]“ geholfen.
In MARC21 gibt es verschiedene Felder mit Unterfeldern, die dazu noch bis zu 2 Indikatoren haben. In Koha wird z.B. das Fled 952 für alle Exemplardaten verwendet. im Unterfeld „p“, also 952$p befindet sich z.B. der Barcode. Im Feld 245$a und 245$b werden der Titel und der Untertitel festgehalten usw. Eine genaue Auflistung in deutsch gibt es bei der [Deutschen Nationalbibliothek][4].
Mehr oder weniger zufällig bin ich auf [pymarc][5] gestoßen, eine Python-Bibliothek zum Bearbeiten von MARC21 Daten. Diese Bibliothek nimmt einem viel Arbeit ab. Ich habe also aus den vorbereiteten Daten die einzelen Einträge der MARC21-Felder erstellt und am Ende als MARC21XML exportiert. Hier ein Auszug aus dem Skript:
```
if "ISBN" in titles[recordID] and titles[recordID]["ISBN"] != "":
record.add_field(
Field(
tag = '020',
indicators = ['',''],
subfields = [
'a', titles[recordID]["ISBN"]
]
)
)
```
Die Felder 000 bis 008 sind besondere Felder in MARC21, deren Bedeutung ich noch nicht 100%ig verstanden habe. Auf jeden Fall ist der „Leader“ ein sehr wichtiges Feld, weil in ihm wichtige Daten über z.B. die Medienart festgehalten sind. Deshalb hier noch ein Auszug, wie ich den Leader konstrukiert habe (anhand des Medientyps):
```
l = list(record.leader)
```
l\[5] = ’n‘ l[6] = ‚a‘ l[7] = ‚m‘ l[9] = ‚a‘ l[17] = ‚7‘ l[18] = ‚a‘ if titles[recordID\]\[„type“\]\[„short“] in („BU“, „ZS“): l[6] = ‚a‘ l[7] = ‚m‘ if titles[recordID\]\[„type“\]\[„short“] in („CD“, „TC“, „HB“): l[6] = ‚j‘ if titles[recordID\]\[„type“\]\[„short“] in („KA“): l[6] = ‚e‘ if titles[recordID\]\[„type“\]\[„short“] in („VI“, „DV“, „DI“, „FI“, „OV“): l[6] = ‚g‘ if titles[recordID\]\[„type“\]\[„short“] in („CR“, „FD“): l[6] = ‚m‘ if titles[recordID\]\[„type“\][„short“] in („SP“, „SO“): l[6] = ‚o‘ record.leader = „“.join(l)
Ein korrekter Leader ist wichtig, da ansonsten in Koha kein Medientyp bei der Suche oder in den Details angezeigt werden.
Nun müssen die Daten noch von MARC21XML nach MARC21 umgewandelt werden. Koha kann zwar auch MARC21XML importieren, aber da hatte ich immer Probleme mit der Kodierung, was sich in Problemen mit Umlauten und Sonderzeichen gezeigt hat. Also habe ich mit Hilfe von [MarcEdit][6] die Daten vom einem Format in das nächste gebracht. Soweit so gut. Jetzt können die Daten in Koha importiert werden. Allerdings möchte ich gern, dass man bei einer Suche oder in der Detailansicht sieht, ob ein Buch bei Antolin verfügbar ist oder nicht. Antolin ist eine Leseplatform für Kinder, wo man zu einem gelesenen Buch ein Quiz machen kann und dafür Punkte bekommt. Ungefähr so soll es am Ende aussehen:
Wie Antolin integriert werden kann und wie man die Ansicht der Ergebnisse anpassen kann, darüber werde ich im [dritten Teil][7] berichten.
[1]: https://zefanjas.de/2017/07/24/umstieg-von-littera-zu-koha-teil-1/
[2]: http://www.ktp.at/mikrobib/doc/bc/BarEtiB.pdf
[3]: http://www.loc.gov/marc/umb/
[4]: http://d-nb.info/996983511/34
[5]: https://github.com/edsu/pymarc
[6]: http://marcedit.reeset.net/
[7]: https://zefanjas.de/2017/09/16/umstieg-von-littera-zu-koha-teil-3/
Soweit so gut. Jetzt können die Daten in Koha importiert werden. Allerdings möchte ich gern, dass man bei einer Suche oder in der Detailansicht sieht, ob ein Buch bei Antolin verfügbar ist oder nicht. Antolin ist eine Leseplatform für Kinder, wo man zu einem gelesenen Buch ein Quiz machen kann und dafür Punkte bekommt. Ungefähr so soll es am Ende aussehen:
Wie Antolin integriert werden kann und wie man die Ansicht der Ergebnisse anpassen kann, darüber werde ich im [dritten Teil][7] berichten.
[1]: https://zefanjas.de/2017/07/24/umstieg-von-littera-zu-koha-teil-1/
[2]: http://www.ktp.at/mikrobib/doc/bc/BarEtiB.pdf
[3]: http://www.loc.gov/marc/umb/
[4]: http://d-nb.info/996983511/34
[5]: https://github.com/edsu/pymarc
[6]: http://marcedit.reeset.net/
[7]: https://zefanjas.de/2017/09/16/umstieg-von-littera-zu-koha-teil-3/
24. July 2017
Umstieg von LITTERA zu Koha – Teil 1
Seit ca. einem Jahr setzen wir an unserer Schule vermehrt auf Open Source Software (ich hatte hier und hier dazu berichtet). Ein großer Vorteil dieser Entscheidung ist die gewonnene Freiheit und Anpassungsfähigkeit. Manche würden das vielleicht auch als Nachteil sehen 🙂 Als Schule hat man bestimmte Anforderungen und Gegebenheiten und so kommt es bei der Auswahl einer Software nicht nur auf die „Features“ an, sondern v.a. auch, wie gut man diese Software konfigurieren, anpassen und in die vorhandene Infrastruktur einbinden kann. Da sehe ich bei Open Source Software einen riesen Vorteil gegenüber kommerzieller Software.